 گذشته از ترجیحات و اقتضائات فردی، این که کدام زبانها برای یاد گرفتن اولویت دارند هم تابع اهمیت جهانی و منطقهای آن زبانهاست هم تابع ساده بودن یادگیریشان. اهمیت این دومی گاهی مغفول میماند. واقعا یاد گرفتن بعضی زبانها بسیار بسیار سادهتر از زبانهای دیگر است.
گذشته از ترجیحات و اقتضائات فردی، این که کدام زبانها برای یاد گرفتن اولویت دارند هم تابع اهمیت جهانی و منطقهای آن زبانهاست هم تابع ساده بودن یادگیریشان. اهمیت این دومی گاهی مغفول میماند. واقعا یاد گرفتن بعضی زبانها بسیار بسیار سادهتر از زبانهای دیگر است.
از انگلیسی و عربی که بگذریم، فکر میکنم برای فارسیزبانها مقرونبهصرفهترین زبان برای یاد گرفتن از لحاظ حاصلضرب آسانی و اهمیت همانا ترکی استانبولی است. قطعا ترکی استانبولی به اندازه زبانهای جهانیای مثل اسپانیولی و چینی پرگویشور نیست و ادبیات و فلسفهاش به اندازه فرانسه و آلمانی دل نمیبرد. اما در مقابل برای ایرانیها اهمیت منطقهای فرامرزی دارد (زبان قدرتمندترین کشور همسایه و یکی از محبوبترین مقاصد سفرهای خارجی برای ایرانیان) و بسیار نزدیک به دومین زبان مهم داخل ایران است (ترکی آذربایجانی). اما مهمتر از اینها، آنچه رتبه ترکی استانبولی را بالا میبرد و علیرغم ضعف پشتوانه سیاسی و اقتصادیاش در مقایسه با زبانهای بزرگ جهان آن را گزینهای معقول برای یادگیری میکند، این است که بسیار بسیار ساده است. تلاش برای یاد گرفتن ترکی استانبولی هزینهای است که بازدهش سریع و شیرین است!
الفبای ترکی استانبولی چون تازهتاسیس است بازتاب بسیار نزدیکی از آواهای این زبان است در نتیجه املا و خواندن در ترکی (بر خلاف زبانهایی مثل انگلیسی و فرانسه و پروژههای سنگینی مثل چینی و ژاپنی) به هیچ عنوان چالش نیستند. ابتنایش هم بر الفبای رایج زبانهای اروپایی است در نتیجه نیاز به کوشش مضاعفی ندارد (بر خلاف مثلا روسی و یونانی). صرف و نحو ترکی خیلی ساده است. نه مثل روسی و عربی نظام نقشدهی پیچیده و پر استثنا دارد، نه مثل فرانسه و آلمانی و اسپانیولی مذکر و مونث دارد و، نه در آن از دشواریهای عجیب و غریبی شبیه ریشههای ثلاثی و رباعی که در عربی و عبری پیدا میشوند خبری هست.
نظام آوایی ترکی استانبولی هم برای فارسیزبانان (و چه بسا همه) بسیار ساده است. برای یک فارسیزبان، ترکی صرفا سه واج ناآشنا (ü و ö و ı) و یک واجگونه ناآشنا (dark L) دارد در حالی که یک فارسیزبان وقتی میخواهد انگلیسی یاد بگیرد با دستکم هشت واج ناآشنا و چندین تغییر جدی در نظام واجگونهها روبهرو میشود. ماجرای تکیه (stress) که خود معضل جداییست که آموختن انگلیسی را به طور ویژه مشکل میکند.
مهمتر از همه اینها، آموختن ترکی استانبولی برای ما آسان است چون درصد واژههایی که با فارسی مشترکند چشمگیر است. در واقع اگر از زبانهای همخانواده نزدیک ترکی (مثل ازبکی و ترکمنی) بگذریم، هیچ زبانی در جهان به اندازه فارسی با ترکی استانبولی از نظر واژگان قرابت ندارد. کافیست الگوهای تغییر واژگان دستمان بیاید تا ناگهان ببینیم که چه تعداد زیادی از کلمههای ظاهرا غریب ترکی را میشناسیم، و به وجد بیاییم از این که Şekil همان شکل است و dert همان درد است و Hüzün همان حزن است و halk همان خلق است و kayıp همان غیب است و قس علی هذا.
خلاصه این که، اگر جهت تفریح یا برنامهریزی برای محل زندگی در آینده یا پژوهشهای تاریخی/اجتماعی یا هر چیز دیگری به زبانهایی که میشود آموخت فکر میکردیم، به نظرم ترکی استانبولی را نباید از قلم بیاندازیم.
بایگانی برچسب: s
این واجگونههای نازنین. از «ک» فارسی تا «ر» هیاکی
 احتمالا اولین خاطرهی زبانشناسانهی من بر میگردد به سال اول دبستان وقتی که متوجه شده بودم که انگار فارسی دو جور «ک» متفاوت دارد. یکی آن که اول «کاسه» است و دیگری آن که اول «کتاب» است و انگار «غلیظ»تر است، یا شاید بشود گفت که کمی به «چ» شبیهتر است. (برای این که تفاوت این دو «ک» را حس کنید مثلا به لهجهی سید محمد خاتمی دقت کنید که تقریبا تمام «ک»ها را مثل «کاسه» تلفظ میکند!) بگذریم که چهقدر این ادعایم مایهی خنده شد و چهقدر آدمها نمیپذیرفتند و من چهقدر مطمئن بودم و چهقدر تا همین پارسال هم بر سر این دو تا «ک» با دوستانم ماجراها داشتم.
احتمالا اولین خاطرهی زبانشناسانهی من بر میگردد به سال اول دبستان وقتی که متوجه شده بودم که انگار فارسی دو جور «ک» متفاوت دارد. یکی آن که اول «کاسه» است و دیگری آن که اول «کتاب» است و انگار «غلیظ»تر است، یا شاید بشود گفت که کمی به «چ» شبیهتر است. (برای این که تفاوت این دو «ک» را حس کنید مثلا به لهجهی سید محمد خاتمی دقت کنید که تقریبا تمام «ک»ها را مثل «کاسه» تلفظ میکند!) بگذریم که چهقدر این ادعایم مایهی خنده شد و چهقدر آدمها نمیپذیرفتند و من چهقدر مطمئن بودم و چهقدر تا همین پارسال هم بر سر این دو تا «ک» با دوستانم ماجراها داشتم.
دو سه سال پیش که داشتم از دوست آذربایجانیام ترکی یاد میگرفتم، در همان جلسهی اول دربارهی هماهنگی واکهای (vowel harmony) در ترکی برایم حرف زد و گفت که باید یاد بگیرم که کدام صداها کلفت (qalın) هستند و کدامها نازک (İncə) چون پسوندها براساس نوع مصوتهای کلمات تعیین میشوند. مثلا برای جمع بستن qız میگوییم qızlar اما برای جمع بستن göz مصوت پسوند جمع از lar به lər عوض میشود و میگوییم gözlər. حفظ کردن اینها و مسلط شدن بر آنها برایم سخت بود چون اصلا به ذهنم آشنا نبود که کسره و فتحه و «ی» در یک گروه قرار بگیرند و ضمه و «و» و «ا» در یک گروه دیگر، چرا که معمولا دستهبندی مصوتها در ذهن خودآگاه فارسیزبانان به شکل دیگری است.
اما نقطهی اوج داستان وقتی بود که یک روز ناگهان متوجه شدم که مصوتهای قالن همانهایی هستند که در فارسی وقتی بعد از «ک» میآیند آن را مثل «ک» در «کاسه» میکنند و مصوتهای اینجه آنهایی هستند که در فارسی وقتی بعد از «ک» میآیند آن را مثل «ک» در «کتاب» میکنند. باورم نمیشد که در فارسی هم بر مبنای همان دستهبندی اتفاقهایی بیفتد.
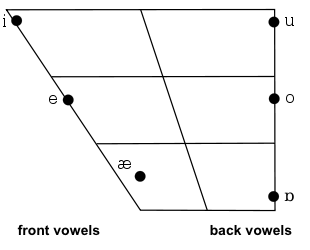
بعدا که درس واجشناسی مقدماتی را با دکتر محرم اسلامی گذراندم، تمام قضایا ناگهان بدیهی شد. مصوتهای «اینجه»، در واقع همان مصوتهای پیشین (front vowels) هستند. یعنی آنهایی که به کمک قسمتهای جلویی زبان تولید میشوند. عجیب نیست که صامت «ک» را هم با خودشان به جلو بیاورند. به این فرآیند که برای «ک» (و البته «گ») در چنین محیطهایی اتفاق میافتد کامی شدن (palatalization) میگویند. (البته به نظرم میرسد که شکل پیشفرض «ک» و «گ» در فارسی همین شکل کامی باشد و در واقع واجگونههای دیگر محصول تغییرند.)
تنها یک نقطهی تاریک در کل این ماجرا باقی ماند، و آن هم یک واژهی استثنایی و البته رکیک (به معنی سرین) است که بسیاری از فارسیزبانها در آن «ک» قبل از «و» را کامی تلفظ میکنند، به خصوص اگر بخواهند رکاکت را دوچندان کنند! به نظر من پدیدهی بسیار جالبیست که در فارسی، آن هم فقط در یک کلمه، آنچه تعیینکنندهی واجگونهی نهایی است مقاصد پراگماتیک است نه محیط واجشناختی. این مورد مدتها به عنوان یک استثنای جالب در ذهنم بود و موردی مانند این نمیشناختم، تا این که دیروز با این مثال جالب از زبان هیاکی (یاکی) آشنا شدم:
در زبان هیاکی (متعلق به بومیان آمریکای مرکزی در مکزیک و آریزونا) «ل» و «ر» دو واجگونهی مختلف از یک واج هستند (یعنی جایگزین کردنشان با هم اختلاف معنایی ایجاد نمیکند). اما نکتهی جالب اینجاست که استفاده از «ل» معمولا بار محبتآمیز و دوستانه دارد در حالی که استفاده از «ر» بار منفی دارد. مثلا کلمهی «moela» به معنی «قدیمی» است اما بار معنایی مثبت دارد. اگر دربارهی چیز قدیمیای صحبت میکنید که دوستش ندارید، به جای آن از واژهی «moera» استفاده میکنید. ظاهرا این نقش برای «ل» و «ر» نظرا در تمام کلمات هیاکی وجود دارد. فکر میکنم هر طور حساب کنیم، ماجرای «ر» و «ل» در یاکی از ماجرای «ک» فارسی هم گستردهتر است، هم هیجانانگیزتر!